In the world of deep learning, neural networks are the backbone of many advanced AI systems. However, these models can often struggle with a common issue—overfitting, where they perform well on training data but fail to generalize to new, unseen data. One of the most effective solutions to this problem is dropout.
This simple yet powerful technique forces neural networks to "forget" certain connections during training, ensuring that they don't become overly reliant on any single feature. By introducing controlled randomness, dropout enhances a model’s robustness, making it more adaptable and effective in real-world scenarios.
The Concept of Dropout in Neural Networks
Dropout is a regularization technique introduced to prevent overfitting in neural networks. At training time, it randomly zeros a fraction of neurons at each iteration so that no neuron can overspecialize and dominate the learning process. The major benefit of this method is that it compels the network to create stronger feature representations by learning redundancies. Instead of letting a small number of neurons get excessively specialized, dropout makes the network as a whole contribute to learning, enabling generalization.
A parameter known as the dropout rate regulates the chances of dropping neurons, generally between 20% and 50%. Increasing the dropout rate implies more neurons are dropped at training time, which makes the network less susceptible to overfitting. However, this slows down learning as fewer neurons contribute to each training step. Finding a balance is necessary to ensure learning efficiency with improved generalization.
Dropout operates differently at the training and inference stages. At training time, randomly dropped neurons do not allow the model to depend on particular pathways, promoting a varied representation of features learned. Inference, but not dropout, is switched off, and all neurons are utilized, but their outputs are normalized to compensate for the missing neurons observed during training. This normalization guarantees that the model performs uniformly without any dropped neurons in actual use.
How Does Dropout Improve Model Robustness?
A neural network without dropout can quickly memorize training data instead of understanding patterns that generalize well to new inputs. When dropout is applied, the network is forced to learn in a way that distributes knowledge across multiple neurons. This makes it less likely to depend on specific neurons that may capture noise instead of useful patterns. As a result, models trained with dropout tend to perform better on unseen data, demonstrating stronger robustness in real-world scenarios.
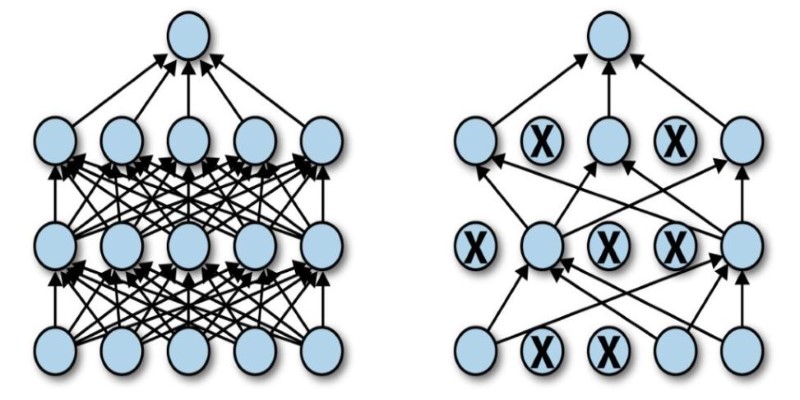
Dropout effectively simulates training multiple smaller networks within the same model. Since different neurons are deactivated at each iteration, the network learns to solve problems through diverse pathways, reducing its dependency on any particular subset of neurons. This process mimics ensemble learning, where multiple models are combined to improve accuracy and reduce variance. Instead of training multiple models separately, dropout achieves similar benefits by dynamically altering the network’s architecture during training.
The impact of dropout is particularly noticeable in deep networks where overfitting is more common. With a large number of layers and parameters, deep networks tend to memorize training examples unless a regularization method like dropout is used. By introducing controlled randomness, dropout forces deeper layers to learn useful patterns instead of memorizing specific examples. This makes neural networks more adaptable and capable of handling various real-world inputs.
Additionally, dropout helps in dealing with noisy datasets. Many real-world datasets contain inconsistencies, errors, or irrelevant variations that can mislead a model. By preventing the network from becoming too sensitive to specific details, dropout ensures that it focuses on essential features, making predictions more stable and reliable. This robustness makes dropout particularly useful in applications like speech recognition, image classification, and medical diagnostics, where input variations can be significant.
Dropout in Practice: Balancing Regularization and Performance
While dropout offers significant benefits, improper use can lead to unintended side effects. A dropout rate that is too high can make learning inefficient since too many neurons are deactivated at each step, leading to slow convergence and underfitting. On the other hand, a dropout rate that is too low might not effectively prevent overfitting, making the network less robust.
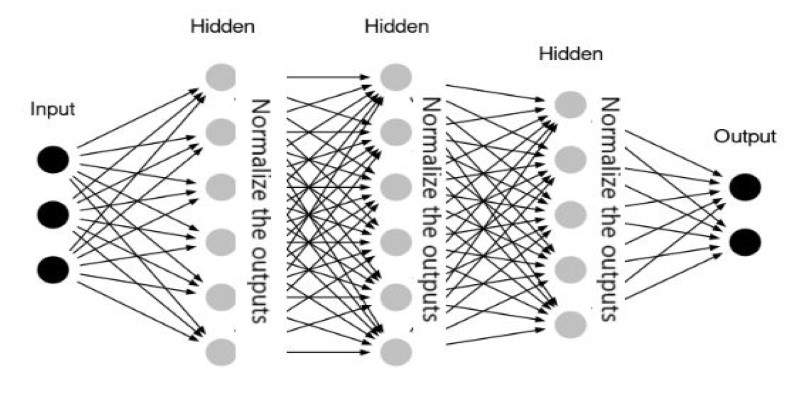
One common approach to optimizing dropout usage is applying it selectively. In many neural networks, dropout is primarily used in fully connected layers rather than convolutional layers. This is because convolutional layers already benefit from weight-sharing mechanisms that improve generalization. Applying dropout to dense layers ensures that the final feature representation remains robust without significantly impacting feature extraction earlier in the network.
Another technique involves gradually reducing dropout as training progresses. This allows the model to explore diverse feature representations in the early stages while stabilizing as it approaches convergence. Some advanced methods, like adaptive dropout, dynamically adjust the dropout rate based on training progress or layer-specific requirements. This fine-tuning ensures optimal regularization without excessively slowing down learning.
Despite its effectiveness, dropout is not the only regularization method available. Techniques like L1 and L2 regularization, batch normalization, and data augmentation can also improve model robustness. In many cases, combining dropout with these methods leads to even better generalization and stability. The key is understanding a model's specific needs and experimenting with different approaches to find the best balance.
Conclusion
Dropout is a powerful technique that improves the robustness of neural networks by randomly deactivating neurons during training. This prevents overfitting and encourages models to generalize better, making them more adaptable to real-world data. While choosing the right dropout rate is essential, it works particularly well in fully connected layers and can be fine-tuned for different network architectures. When combined with other regularization methods, dropout enhances stability and performance. As AI continues to advance, dropout remains a vital tool for creating reliable, high-performing neural networks that can handle diverse and unpredictable real-world scenarios.