In the world of machine learning, there are many algorithms to choose from, each designed for specific tasks. One of the most popular and powerful algorithms is the random forest. Known for its high accuracy and versatility, random forests are used for a variety of tasks, including classification and regression.
But like any machine learning model, it comes with its own set of advantages and disadvantages. In this article, we will delve into these aspects of the random forest algorithm, helping you understand when and why it might be the right choice for your data.
What Is a Random Forest?
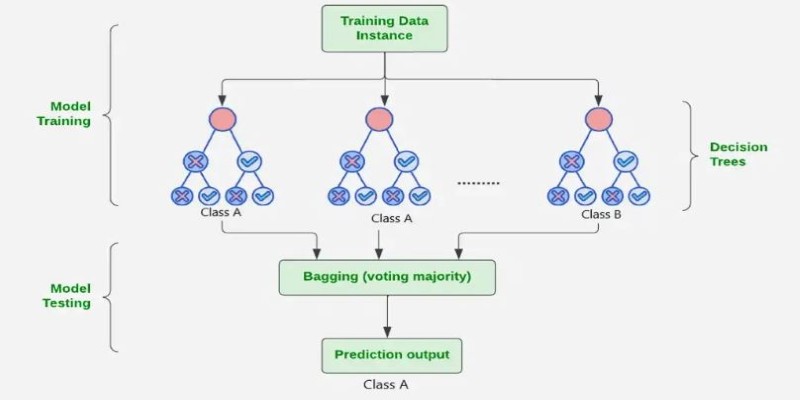
Before discussing its advantages and disadvantages, let's first define a random forest. A random forest is an ensemble learning algorithm, which means it combines multiple individual models to create a stronger overall model. Specifically, a random forest consists of a collection of decision trees. Each decision tree is trained on a random subset of the data, and the final prediction is based on the aggregate of all trees' predictions.
This "forest" of decision trees limits the risk of overfitting, a situation inherent in machine learning models. Because each tree learns from a diverse subset of data, the model is able to generalize more efficiently and make sounder predictions in unseen data.
Advantages of Random Forest
Random forests have a variety of advantages that make them a valuable asset in machine learning. Whether you're dealing with big data or want a model that's less likely to overfit, random forests provide a consistent solution. Some of the most important benefits are listed below:
High Accuracy
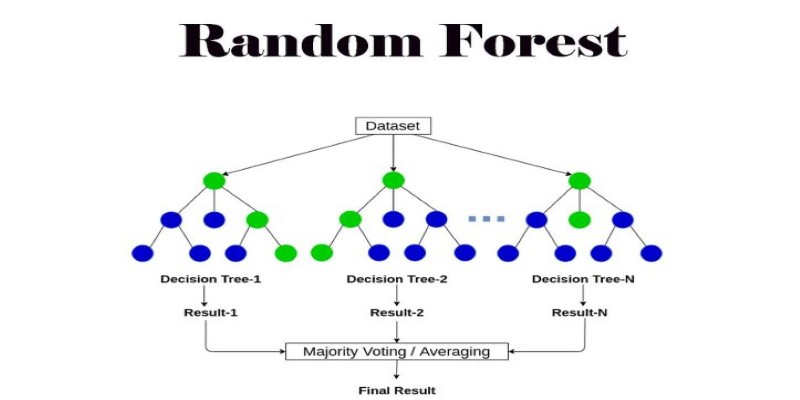
One of the random forest algorithm's strongest strengths is that it can generate extremely accurate results. As opposed to employing a single decision tree, it is less prone to overfitting by averaging the predictions of several decision trees. This precision is particularly important when dealing with complicated datasets that need a model to detect subtle patterns.
Robust to Overfitting
Overfitting occurs when a model overcomplicates itself, picking up noise rather than actual patterns. Random forests minimize this risk with bagging (Bootstrap Aggregating), where every tree is trained on a different subset of the data. This reduces overfitting, making the model more stable to data fluctuations, particularly in real-world applications with noisy or unreliable data.
Handles Large Datasets Well
Another advantage of random forests is their ability to scale with large datasets. When dealing with huge volumes of data, random forests can still perform efficiently and generate accurate predictions. They are particularly useful when handling datasets that contain both categorical and numerical data, offering flexibility that many other algorithms cannot match.
Feature Importance
Random forests allow easy assessment of feature importance by evaluating how each feature reduces uncertainty or "impurity" in decision trees. This helps identify the most predictive features, guiding data preprocessing decisions. By focusing on the most impactful variables, you can improve model performance and ensure that the most relevant factors are considered in the analysis.
Flexibility for Classification and Regression
Random forests are versatile enough to handle both classification and regression tasks. This means that regardless of whether your problem involves predicting a category (such as classifying emails as spam or not spam) or predicting a continuous value (such as house prices), random forests can be applied effectively.
Parallelization Capability
Since the individual decision trees in a random forest are independent, the model can be parallelized, meaning it can be distributed across multiple processors or machines. This significantly speeds up computation times, making random forests an excellent choice for large-scale data analysis.
Disadvantages of Random Forest
Despite the many benefits, there are also some important drawbacks to consider when using random forests. These limitations can impact how and when the model should be applied. Below are some of the main disadvantages:
Complexity and Lack of Interpretability
A significant disadvantage of random forests is their lack of interpretability. Unlike a single decision tree, which clearly outlines the decision-making process, random forests function as a "black-box" model. While they offer high accuracy, it’s difficult to understand how the model arrived at specific decisions. In industries like healthcare, finance, or law, where transparency is essential, this lack of clarity can be a serious drawback.
Computationally Expensive
Random forests can be computationally expensive, especially with large datasets. Each tree requires independent training, consuming significant memory and processing power. This can be problematic for systems with limited resources or when quick model deployment is needed. Compared to simpler models like linear regression, random forests may be less practical in resource-constrained settings.
Difficulty with Extrapolation
While random forests excel at interpolation—predicting values within the range of the training data—they tend to struggle with extrapolation or predicting values that lie outside the training data range. This makes them less suitable for scenarios where the model needs to predict rare events or values that are far removed from the training data.
Sensitive to Noisy Data
Although random forests are robust to overfitting, they are not entirely immune to the effects of noisy data. If your dataset contains a lot of irrelevant or misleading features, the performance of the random forest model can degrade. While individual decision trees might be overfitted to noise, the random forest approach does help, but excessive noise can still impact the model's ability to make accurate predictions.
Limited Insight into Feature Relationships
Random forests are great for assessing the importance of individual features, but they do not provide detailed insights into how those features interact with each other. In some cases, understanding the relationships between different features is essential, and random forests do not offer the transparency needed for such analysis.
Conclusion
The random forest algorithm offers numerous advantages, such as high accuracy, flexibility, and the ability to handle large datasets. It reduces overfitting and allows for easy feature importance analysis. However, its complexity and lack of interpretability, along with the computational resources it demands, can be significant drawbacks. By weighing these pros and cons, you can make an informed decision about when and how to apply random forests effectively to address specific challenges in your machine-learning tasks.