Machine learning models thrive on data, but their performance isn’t just about feeding more information into the system. A common challenge in training these models is finding the right balance between bias and variance. Too much bias makes a model oversimplified and unable to capture patterns, while excessive variance makes it too sensitive to data fluctuations, leading to poor predictions.
This tradeoff directly influences how well a model generalizes to new, unseen data. Striking the right balance between bias and variance is the key to building models that are neither too rigid nor too erratic. Understanding these concepts is critical to optimizing machine learning algorithms and preventing pitfalls such as overfitting and underfitting.
Understanding Bias in Machine Learning
Bias represents the model's tendency to simplify problems excessively. A high-bias model assumes strong general rules about the data, often ignoring finer details. This leads to underfitting, where the model fails to capture relevant patterns and makes poor predictions on both training and test data.
A classic example of high bias is linear regression applied to a non-linear dataset. If the underlying relationship between variables is complex but the model assumes it’s a straight line, it won’t capture the real structure, leading to significant errors. Similarly, decision trees with severe pruning or shallow neural networks may also struggle with bias issues.
Bias tends to result from selecting an overly simplified model or applying limited features. For example, training a spam classifier based solely on word frequency may not accurately capture subtle language patterns. The idea is to retain some degree of bias for generalization while not allowing the model to be so simplistic.
Variance and Its Impact on Machine Learning Models
Variance is the reverse of bias and indicates a model's sensitivity to variations in training data. Variance is a high-variance model that identifies even small things, usually accommodating noise instead of actual patterns. This results in overfitting, where a model performs amazingly well on the training data but does poorly on new data.
Imagine training a deep neural network on a small dataset. If the model has too many layers and parameters, it may memorize specific data points rather than generalizing patterns. As a result, it may fail to make accurate predictions when tested on new examples. Decision trees with deep splits or polynomial regression models with excessive terms also suffer from high variance.
One sign of variance issues is a drastic difference between training and test performance. A model with near-perfect accuracy on training data but poor test results likely overfits. Techniques like cross-validation help detect these discrepancies and provide ways to adjust the model accordingly.
The Bias-Variance Tradeoff and Generalization
Finding the right balance between bias and variance is crucial for building machine learning models that perform well on new data.
The Balance Between Bias and Variance
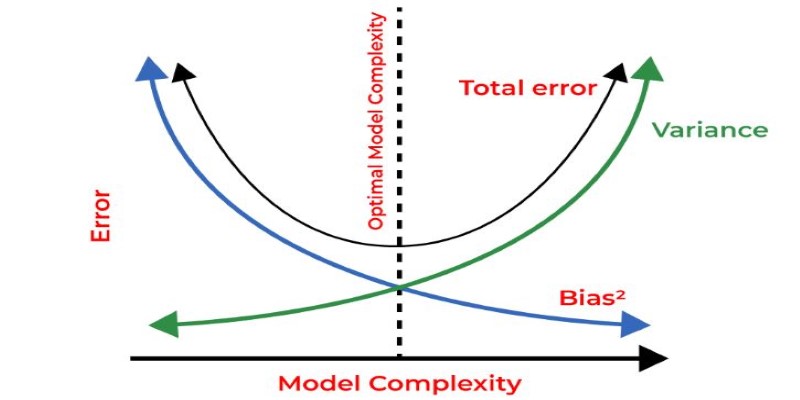
The relationship between bias and variance creates an inevitable tradeoff in machine learning. If a model is too simple (high bias), it won’t learn enough from the data. If it’s too complex (high variance), it learns too much, including irrelevant noise. The ideal model finds a middle ground, balancing bias and variance to achieve optimal generalization.
Understanding Generalization Error
One way to visualize this tradeoff is through the generalization error, which consists of bias error, variance error, and irreducible error. While irreducible error is inherent noise in the data that no model can eliminate, the goal is to minimize bias and variance simultaneously.
Strategies to Achieve Balance
Achieving this balance involves multiple strategies. Regularization techniques like L1 (Lasso) and L2 (Ridge) penalties help reduce variance by constraining model complexity. Ensemble methods, such as bagging and boosting, combine multiple weak models to improve robustness. Feature selection ensures that only relevant inputs contribute to learning, preventing unnecessary complexity.
Adjusting Training Data and Hyperparameters
Another approach is adjusting training data volume. A high-variance model benefits from more data, as additional examples help smooth out fluctuations. Conversely, a high-bias model may require more expressive features or a more complex architecture to improve learning.
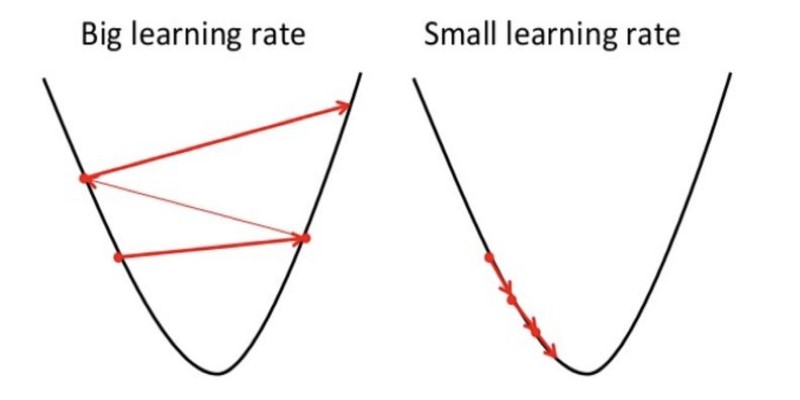
Fine-tuning hyperparameters also plays a significant role. For neural networks, tweaking learning rates, dropout layers, or batch sizes influences how bias and variance interact. Decision trees benefit from setting constraints on depth, while support vector machines require careful kernel selection to avoid overfitting.
Strategies to Reduce Bias and Variance
Reducing bias and variance requires targeted strategies tailored to the specific problem. For bias reduction, increasing model complexity helps capture more patterns in the data. Switching from linear regression to decision trees or deep learning models can improve performance when simple models underfit. Additionally, incorporating more relevant features ensures the model has enough information to learn effectively.
For variance reduction, regularization techniques help prevent models from memorizing noise. L1 and L2 regularization penalizes large coefficients, ensuring simpler and more generalizable models. Data augmentation and dropout methods in deep learning help reduce overfitting by exposing models to more variations. Cross-validation provides an essential safeguard, allowing performance assessment on different data subsets to detect overfitting early.
Ultimately, the right balance depends on the problem, dataset size, and model type. Experimentation and iterative tuning remain essential for achieving an optimal tradeoff between bias and variance, leading to more accurate and generalizable machine learning models.
Conclusion
Balancing bias and variance is fundamental to creating machine learning models that generalize well. Too much bias results in underfitting, where the model oversimplifies patterns, while excessive variance leads to overfitting, making the model too sensitive to training data. The key to solving this challenge lies in adjusting model complexity, regularizing parameters, and ensuring adequate data quality. The tradeoff is unavoidable, but with careful tuning, machine learning models can achieve high accuracy without sacrificing generalization. Understanding and managing this dynamic ensures robust models capable of making reliable predictions in real-world applications.