AI is evolving fast, but one thing remains clear—it struggles to understand human intent the way people do. Traditional models crunch numbers and analyze patterns, but they often miss the subtleties of human judgment. That's where Reinforcement Learning from Human Feedback (RLHF) changes the game. Instead of relying solely on raw data, RLHF teaches AI by incorporating real human preferences, making it more intuitive and aligned with human values.
Whether it’s chatbots, content moderation, or decision-making systems, RLHF ensures AI responds in ways that feel more natural, ethical, and useful. It’s AI learning, not just from data, but from us.
How Does Reinforcement Learning From Human Feedback Work?
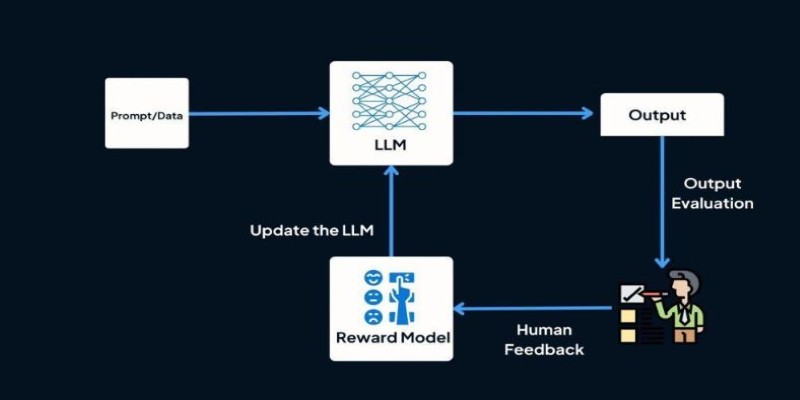
Reinforcement Learning (RL) is a machine learning method in which an AI agent explores an environment and learns through rewards or punishment. In a standard RL framework, AI optimizes its decision-making approach by maximizing desirable outcomes and minimizing undesirable ones over time. While effective in structured environments like game playing or robotics, traditional RL struggles with tasks requiring human-like understanding, where decisions are not purely mathematical but ethical and contextual.
RLHF enhances this process by adding human feedback as a guiding factor. Instead of allowing the AI to determine what is "correct" purely based on numerical rewards, humans provide evaluations of AI-generated responses. This feedback is then used to train a reward model, helping the AI prioritize human-preferred responses in the future. For example, when training a conversational AI, human reviewers rank different responses based on clarity, relevance, and tone. The AI then learns to generate responses that align more closely with human expectations, leading to a more natural and useful interaction.
One of the most significant applications of RLHF is in the training of AI language models such as ChatGPT. Human reviewers are used to fine-tune responses by ranking various outputs and to ensure that AI does not output misleading, biased, or unsuitable content. This fine-tuning process has dramatically enhanced AI's capability to output more relevant and human-like responses in practical applications.
The Benefits of RLHF in AI Development
The introduction of human feedback in AI training has revolutionized how AI models function. Here’s why RLHF is becoming a crucial part of AI development:
Improved Ethical Decision-Making

Traditional AI models optimize for efficiency and performance, but they often lack a moral compass. RLHF helps AI recognize ethical considerations by incorporating human input on sensitive topics, ensuring AI-generated content is not only accurate but also responsible.
Reduction of AI Bias
AI models trained on historical data can inadvertently learn and reinforce biases. By incorporating human oversight, RLHF can help identify and correct biases in AI decision-making. This is particularly important in applications like hiring algorithms, loan approvals, and content recommendations, where fairness is essential.
Alignment with Human Preferences
AI models need to understand subtle human nuances, such as tone, intent, and emotional context. RLHF helps bridge the gap between machine logic and human expectations, improving AI’s ability to interact naturally with users in chatbots, customer service, and virtual assistants.
Enhanced AI Adaptability
RLHF makes AI models more flexible and adaptable to different industries. Whether it’s a legal AI reviewing contracts, a medical AI assisting in diagnostics, or a self-driving car making split-second decisions, human feedback refines AI responses to suit real-world challenges.
Challenges of Implementing RLHF
Despite its advantages, RLHF has its own set of challenges. One of the biggest hurdles is scalability. Unlike fully automated training processes, RLHF requires human involvement, which can be costly and time-consuming. Training AI models with human evaluations involve extensive labor, making it difficult to implement at scale for every AI system.
Another issue is subjectivity. Human reviewers might have different opinions on what constitutes a "good" response, leading to inconsistencies in training data. Addressing this requires careful curation of human input to ensure that AI learns from a diverse range of perspectives.
Additionally, RLHF does not eliminate the risk of AI generating misleading or harmful content. While human feedback can reduce such occurrences, AI still requires continuous monitoring and updates to ensure it remains aligned with evolving societal values.
The Future of AI with RLHF
The role of RLHF in AI development is only growing. As AI becomes more embedded in daily life, there is a greater need for models that understand and respect human values. From healthcare to education and content moderation, RLHF is helping AI make decisions that are not only intelligent but also ethical and user-centric.
In healthcare, AI-powered diagnostics and treatment recommendations benefit from human oversight to ensure both accuracy and patient safety. In journalism and social media, RLHF aids in filtering misinformation while maintaining balanced and fair content moderation. Even in creative industries, AI models trained with RLHF can generate music, literature, and visual art that better reflect human tastes and emotions.
Ultimately, RLHF is leading AI development toward a future where machines do more than just compute—they understand. As researchers refine this technique, we can expect AI to become more ethical, reliable, and aligned with human intent. While challenges remain, the progress in RLHF demonstrates that AI is not just learning from data—it’s learning from us.
Conclusion
Reinforcement Learning from Human Feedback (RLHF) is transforming AI by ensuring it aligns with human values, making it more ethical, adaptable, and user-centric. By integrating human oversight, AI models move beyond rigid data-driven decisions to a more intuitive understanding of real-world applications. This approach enhances accuracy, reduces bias, and refines AI interactions across industries like healthcare, social media, and automation. While challenges such as scalability and subjectivity persist, RLHF remains a vital tool in AI development. As AI continues evolving, human-guided learning will play an essential role in shaping responsible, reliable, and ethical AI systems that truly serve humanity.