Deep learning models have revolutionized artificial intelligence, enabling machines to recognize patterns, process language, and make decisions. At the core of these models are activation functions—mathematical operations that determine how neurons process inputs. One of the widely used functions is the Tanh activation function, known for its ability to scale inputs between -1 and 1.
Its zero-centered property assists in optimizing learning in neural networks by maintaining balanced outputs, making it the go-to option for most applications. Knowledge of its properties, applications, and limitations is necessary for creating effective deep-learning models.
Understanding the Tanh Activation Function
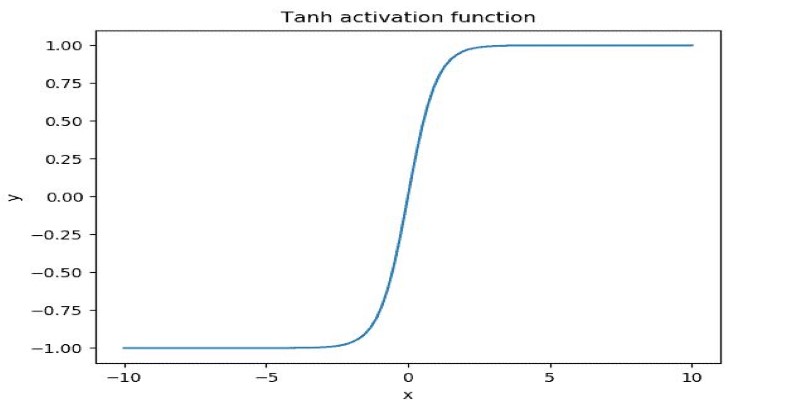
Activation functions dictate whether a neuron should activate based on input signals. The Tanh activation function, or hyperbolic tangent function, transforms an input 𝑥 using the formula:
This function outputs values between -1 and 1, making it distinct from the sigmoid function, which produces values only between 0 and 1. The ability to include negative values makes Tanh more suitable for neural networks that require balanced data distributions.
When the input is close to zero, Tanh acts nearly linearly, enabling smooth gradient flow and stable learning. When input values become increasingly extreme (either very positive or very negative), though, the function saturates, and gradients become extremely small. This problem, the vanishing gradient problem, inhibits learning in deep networks.
Despite this, Tanh remains popular due to its zero-centered outputs, which assist in preventing biased learning in networks. Compared to sigmoid, it facilitates stronger gradient updates when inputs approach zero, resulting in better training efficiency in certain instances.
Why Use Tanh in Deep Learning?
The Tanh activation function is preferred for several reasons. Its zero-centered output aids in effectively training deep networks by preventing activations from building up too much bias. On the other hand, functions such as sigmoid produce only positive values, which can make training slow by leading to gradients that shrink asymmetrically.
Another major benefit is that Tanh provides stronger gradients than sigmoid, leading to better weight updates. This is particularly helpful in networks where faster convergence is needed. Additionally, in models where input values range from negative to positive, Tanh helps retain symmetry, improving network stability.
However, Tanh is not without its downsides. One of the biggest concerns is gradient saturation—when outputs are near -1 or 1, the gradient becomes close to zero, leading to minimal weight updates. This issue becomes more prominent in deep networks, where small gradients in earlier layers can hinder overall learning.
To overcome this, modern architectures often prefer ReLU (Rectified Linear Unit), which does not saturate for positive inputs and allows for efficient gradient propagation. However, ReLU has its problem—neurons can become permanently inactive when outputs are zero, an issue known as the dying neuron problem. Because of this, Tanh remains relevant in cases where negative values are needed or when a balanced activation range is beneficial.
Applications of the Tanh Activation Function
Despite the growing preference for ReLU-based models, the Tanh activation function remains relevant in deep learning, particularly in recurrent neural networks (RNNs). These networks handle sequential data, making Tanh’s ability to balance positive and negative values beneficial for tasks like speech recognition and language modeling. Mapping outputs between -1 and 1 helps stabilize learning and prevents shifting activations toward only positive values.
In natural language processing (NLP), Tanh is used in sentiment analysis and word embedding models, where distinguishing between positive and negative associations is crucial. Its ability to represent both polarities effectively makes it superior to sigmoid in text-based applications.
Tanh also plays a role in image processing, particularly in grayscale image recognition. Since pixel values range from negative to positive intensities, Tanh can help improve contrast adjustments and enhance pattern recognition in Convolutional Neural Networks (CNNs).
Additionally, autoencoders—neural networks designed for feature learning and dimensionality reduction—often rely on Tanh to encode and decode data efficiently. Its ability to preserve both negative and positive activations makes it suitable for data compression and reconstruction tasks, further extending its use in unsupervised learning applications.
Limitations and Alternative Activation Functions
While the Tanh activation function offers several advantages, it has notable limitations that can affect deep learning model performance. One of the primary drawbacks is gradient saturation, which occurs when outputs approach -1 or 1, leading to vanishing gradients. This slows down weight updates and makes training inefficient, particularly in deep networks with multiple layers.
Another challenge is computational cost. Since Tanh involves exponential calculations, it is more complex to compute compared to ReLU (Rectified Linear Unit), which only requires simple thresholding operations. In large-scale neural networks, where efficiency is a concern, models often favor computationally cheaper activation functions.
Alternative activation functions like Leaky ReLU have been introduced to address these issues. Leaky ReLU allows small negative values instead of zero, preventing neurons from becoming inactive. Another alternative, ELU (Exponential Linear Unit), retains some of Tanh’s benefits while reducing gradient saturation, leading to more stable training.
Despite these alternatives, Tanh remains relevant in specific applications. It is still widely used in GANs (Generative Adversarial Networks) for producing smooth outputs and in RNN-based models, where its zero-centered nature helps maintain balanced learning. The choice of activation function ultimately depends on the specific needs of the neural network architecture.
Conclusion
The Tanh activation function remains an important tool in deep learning, particularly for tasks that benefit from balanced positive and negative outputs. While it faces competition from ReLU due to issues like gradient saturation, its zero-centered nature makes it valuable in RNNs, NLP applications, image processing, and autoencoders. Though modern deep learning architectures often favor ReLU for its efficiency, Tanh still holds relevance in specific cases where symmetrical activation is beneficial. Choosing the right activation function depends on the network's requirements, and Tanh continues to be a viable option for models that require well-balanced and stable learning.